



Is er ergens een grotere schat aan taalmaterialen te vinden dan het internet? Ik denk het niet. Maar die schat is ook erg chaotisch: vergelijk het met een enorme stapel kleren waar je een net ensemble uit moet vissen. Je bent er zeker van dat ensemble er is, ergens in die stapel. De kunst is het te vinden.
Gelukkig houdt daar de vergelijking op en bestaan er voor dat internet flink wat tools die orde in de chaos scheppen. Of die op zijn minst een selectie maken van materiaal dat voor jou interessant kan zijn. Een zoekmachine als Google is zo’n hulpmiddel, zeker als je het heel goed kunt inzetten. En het is niet het enige.
Voor mijn variatieonderzoek maak ik vaak gebruik van internetbronnen die voor iedereen vrij toegankelijk zijn. Je moet je er hooguit een keer voor registeren.
Als ik wil nagaan of een bepaald woord of bepaalde combinatie gangbaarder is in Vlaanderen dan in Nederland, of omgekeerd, zoek ik die eerst op via Google. Ik combineer de zoekterm in kwestie met de opdracht ‘site:.be’ en daarna nog eens met ‘site:.nl’. Op die manier krijg ik alleen sites met extensie .be (in principe Belgische sites) dan wel met .nl (in principe Nederlandse sites) te zien die mijn zoekwoord bevatten. Een woordcombinatie zet ik tussen dubbele aanhalingstekens. Ik kijk dan naar het aantal sites dat het woord of de combinatie bevat. Als het aantal zoekresultaten hoog is en het verschil heel groot, dan heb ik waarschijnlijk te maken met een noord-zuidverschil.
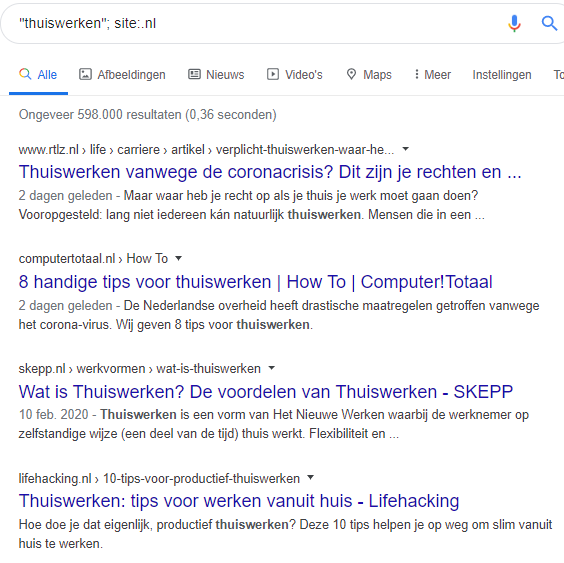
Opgelet hierbij: niet elke .be-site is van een Belgische firma of persoon en niet elke .nl van een Nederlander. Internationale bedrijven registreren verschillende extensies (zo heet dat stukje na de punt in webadressen) voor hun website, maar maken lang niet altijd aparte versies voor de verschillende landen. Daarom zijn die resultaten ook alleen relevant als het verschil heel groot is.
Google Trends
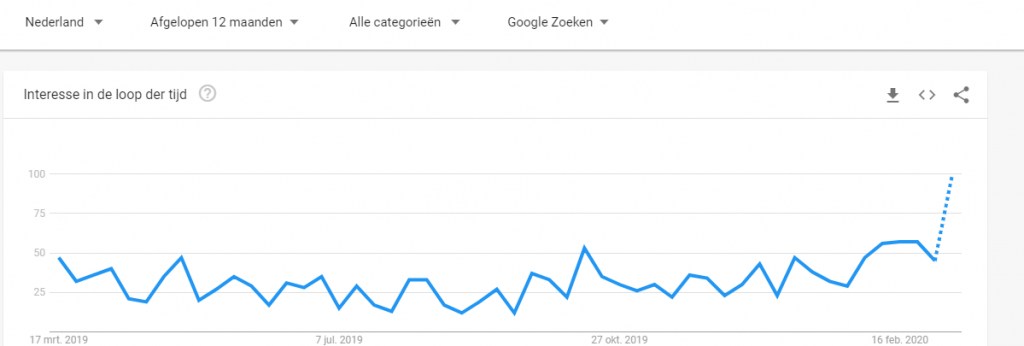
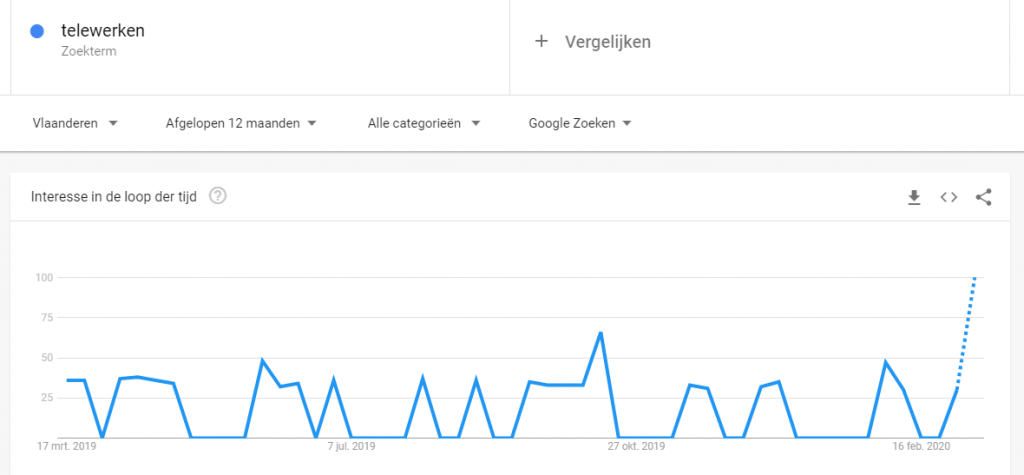
Google Trends is een site van Google zelf waarin iedereen kan opzoeken welke woorden mensen gebruiken om dingen op het internet op te zoeken. Dat is niet hetzelfde als de zoekmachine zelf, waarbij je net opzoekt welke woorden vaak op sites staan. In die zin is het dus betrouwbaarder dan de zoekmachine. Google Trends heeft twee heel leuke toepassingen: je kunt specifiek op land en zelfs regio zoeken (Vlaanderen is zo’n ‘regio’) en je kunt meerdere termen naast elkaar opzoeken. Dat gaat zo.
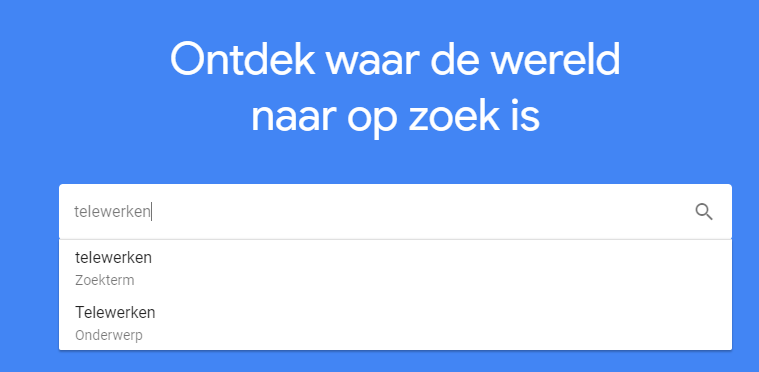
- Je opent Google Trends op trends.google.com
- Je voert een zoekterm in
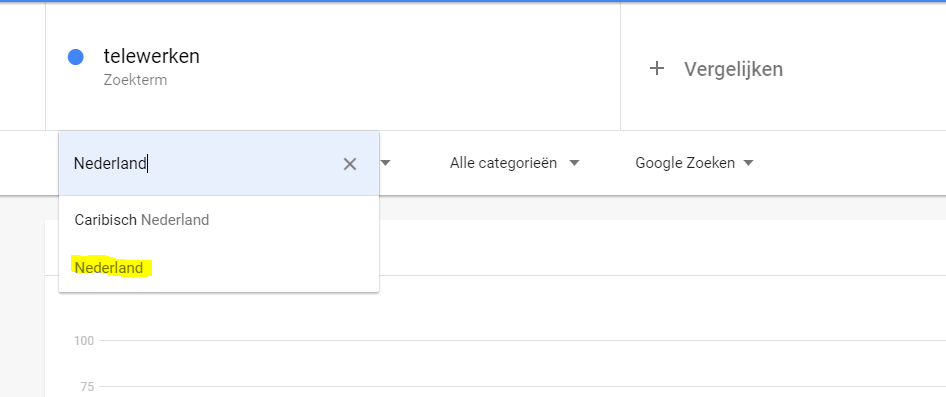
- Je kiest een land (Nederland)
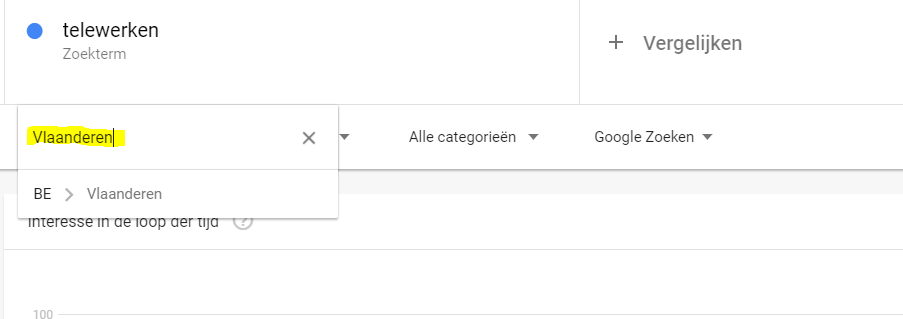
- of een regio (Vlaanderen)
- Je drukt op enter en ziet het resultaat voor je gekozen land/regio. Als je het resultaat voor het andere land / de andere regio wil zien, pas je land/regio aan.
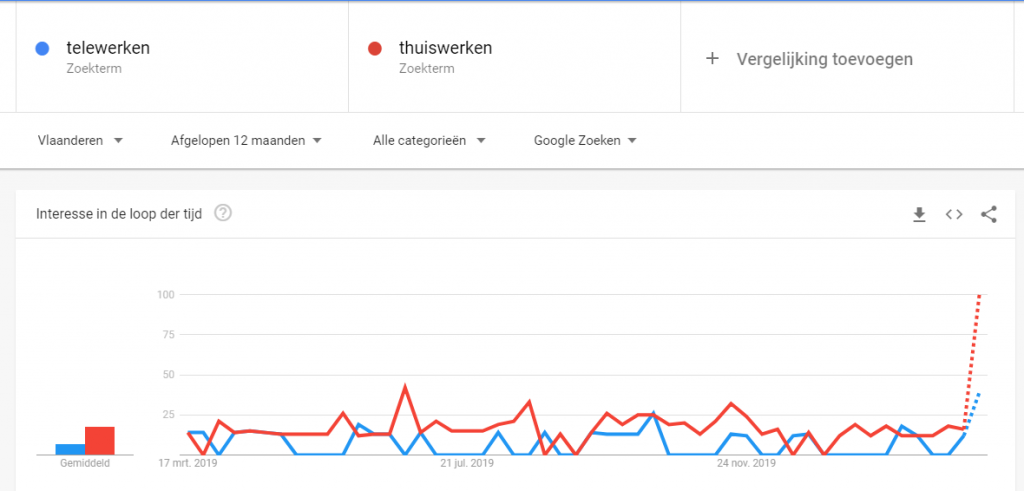
- Nu kun je gaan spelen. Je kunt zoektermen toevoegen en vergelijken:
- Je kunt de onderzochte periode – standaard 12 maanden – langer of korter maken
- Er zijn nog een hoop mogelijkheden, maar het zou me te ver leiden om die hier allemaal op te sommen. Dit zijn alvast de belangrijkste functies
OpenSonar en het Corpus Hedendaags Nederlands
OpenSonar is het resultaat van een groot wetenschappelijk project van enkele jaren geleden. Het is een databank die ongeveer een half miljard Nederlandse woorden bevat en waarvan de bronnen (kranten, tijdschriften, blogs, ondertitels, gesproken taal, …) geannoteerd zijn. Dat betekent dat we van elke bron weten wat voor bron het is, van welk jaar, uit welk land, enz. Daardoor is de databank heel geschikt voor variatieonderzoek. Het Corpus Hedendaags Nederlands is wat kleiner, maar recenter (2017-2018). Het bevat vooral materiaal uit kranten. Ik gebruik deze databanken elke keer wanneer ik de indruk heb dat een bepaald woord of bepaalde combinatie gangbaarder is in het ene deel van het taalgebied en ik bevestiging nodig heb.
Om die twee sites te kunnen gebruiken, moet je eerst een login aanvragen bij het Instituut voor de Nederlandse Taal. Je krijgt die login gratis als je geen commercieel gebruik maakt van die sites. Met andere woorden: je mag er geen dingen mee gaan ontwikkelen die je nadien wil verkopen. Een keer je je logingegevens hebt, kun je ermee aan de slag.
Dit is het zoekvenster van OpenSonar:
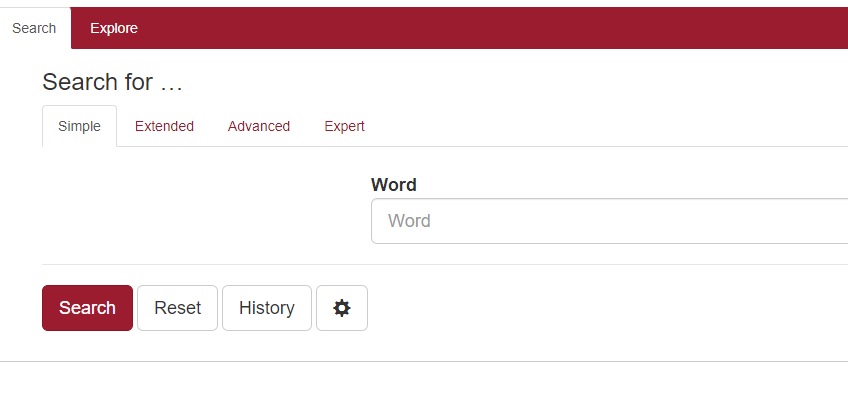
Er zijn heel wat zoekmogelijkheden, maar ik gebruik altijd ‘Simple’. Een eenvoudige zoekopdracht levert dit resultaat op:
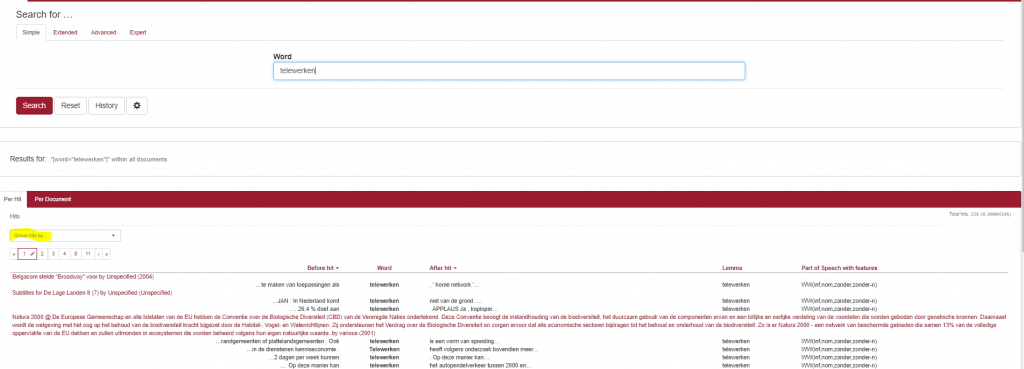
Als je nu wil weten of het woord ‘telewerken’ populairder is in Vlaanderen dan in Nederland, of omgekeerd, kies je bij het gemarkeerde zoekveld voor ‘Group by Country).
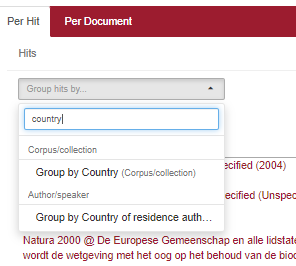
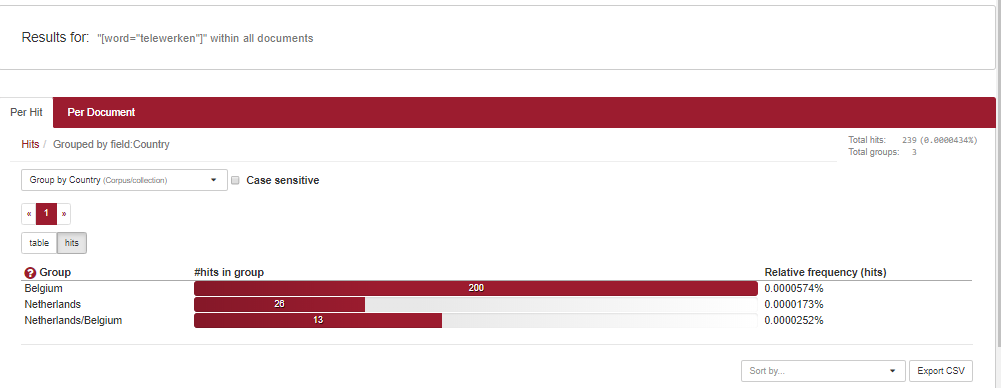
Dat levert voor ‘telewerken’ dit resultaat op:
Het Corpus Hedendaags Nederlands (CHN) werkt een beetje anders:
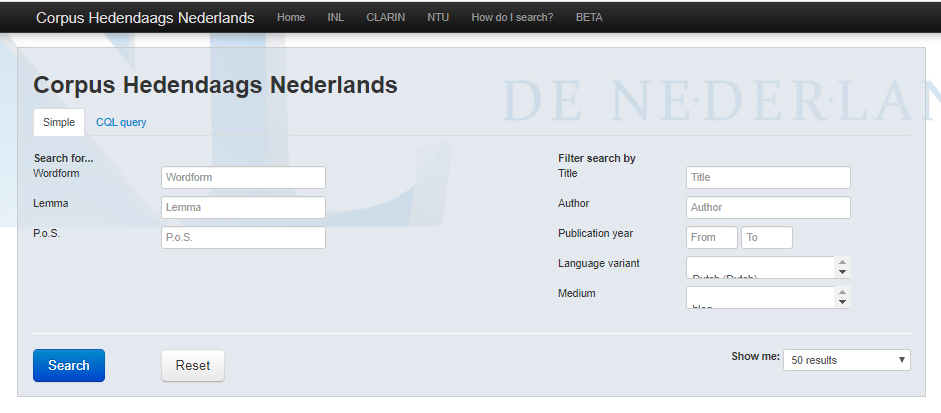
Als je je zoekterm invoert, onder ‘Wordform’ of ‘Lemma’, krijgt je alle resultaten. Rechts boven het lijstje resultaten zie je het aantal. Daarna kun je gaan filteren op bijvoorbeeld ‘Language variant’:
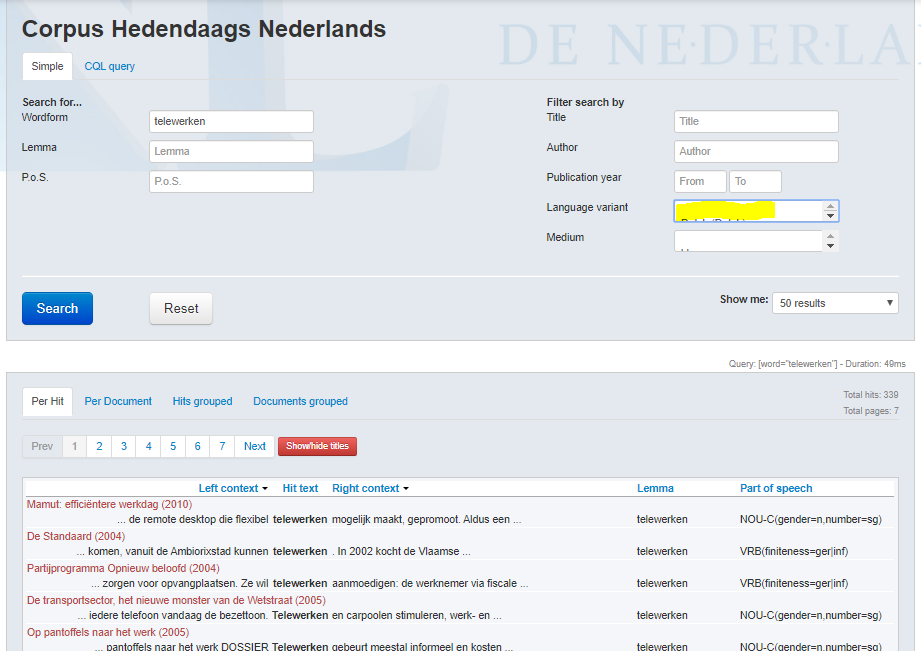
‘Dutch (Dutch)’ levert 136 resultaten op, ‘Dutch (Belgian) 202. Uit die verhouding kun je concluderen dat ‘telewerken’ ook in het CHN frequenter is in Vlaanderen dan in Nederland.
ngram Viewer DBNL
Een laatste gratis online speeltje voor taalvariatie-onderzoek in het Nederlands is de ngram viewer van de Digitale Bibliotheek voor de Nederlandse Letteren (DBNL). Hiermee kun je kijken hoe vaak een bepaald woord of een bepaalde woordcombinatie voorkomt in de honderden documenten die in de DBNL zitten, van 1500 tot nu.
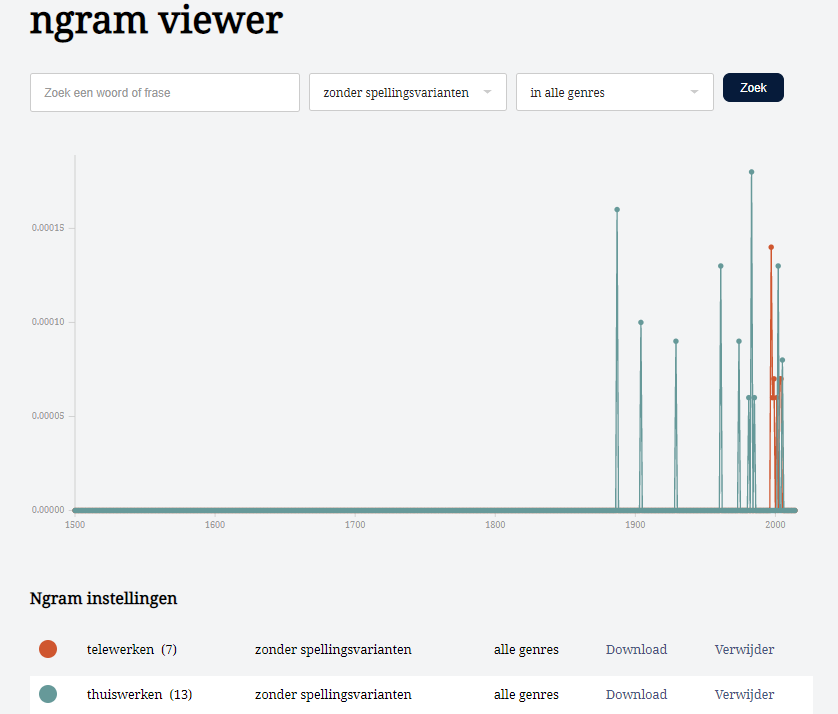
Je kunt kiezen voor de versies met en zonder spellingvarianten en filteren op genre. Filteren op land of regio is hier niet mogelijk.
Dit zijn op dit moment mijn belangrijkste hulpmiddelen die ik inzet als ik snel wil nagaan of er bijvoorbeeld een noord-zuidverschil is, of wil weten wanneer een woord in gebruik is, was of is gekomen. Ik wens jullie er veel plezier mee!

